Enterprise AI
Integration Services
Build secure AI integrations, custom LLM agents, and private RAG pipelines. We bridge enterprise databases with foundational AI models while ensuring absolute data sovereignty.
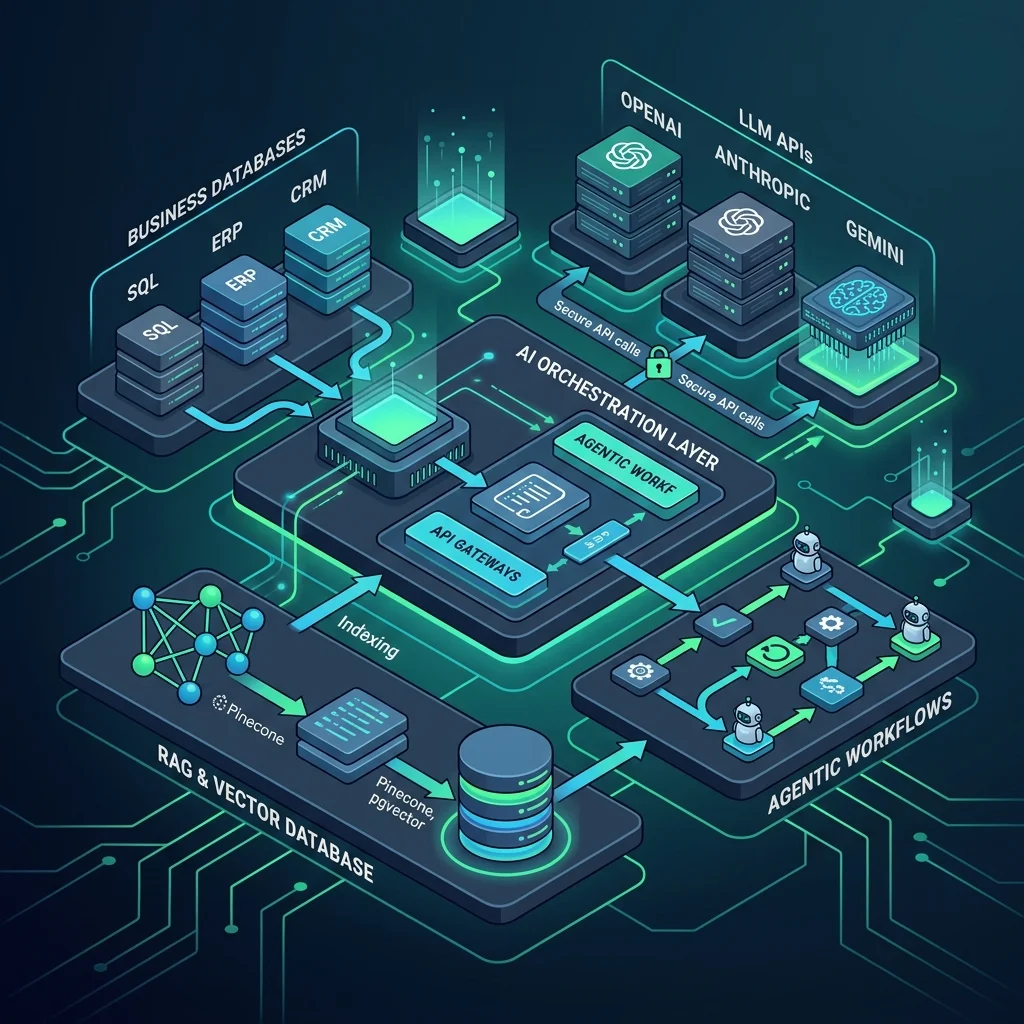
What is AI Integration?
AI integration is the process of embedding artificial intelligence models (such as Large Language Models or specialized machine learning algorithms) directly into existing software, databases, and enterprise systems. Instead of operating as a standalone application, integrated AI automates background workflows, processes unstructured datasets, and delivers intelligent user experiences in real time.
Statum's AI integration consulting services ensure your organization implements AI securely, cost-effectively, and with robust, production-grade architecture that scales to thousands of concurrent users.
Core AI Integration Scenarios
We consult and implement across three primary AI domains to match your specific business requirements:
Generative AI & LLMs
Natural Language Workflows
Embedding models like OpenAI GPT, Google Gemini, Anthropic Claude, or open-weights alternatives (Llama 3, Mistral) into your workflows. Typical applications include automated customer support, document analysis, programmatic content generation, and intelligent database querying using Natural Language.
Machine Learning & Analytics
Predictive Algorithms
Integrating specialized models (built using scikit-learn, TensorFlow, or PyTorch) into core financial or communication software. We support building predictive models for credit scoring, churn analysis, transaction fraud detection, and SMS routing optimizations.
Cognitive & Computer Vision
Visual & Speech Extraction
Connecting structured OCR pipelines for identity card document extraction, automated receipt parsing, multilingual translation, text-to-speech services, and voice verification into customer onboarding portals.
Resilient Architecture
for AI Systems
AI APIs differ from standard database queries due to higher latency, token-based pricing, and model rate limits. We implement best-practice architectures to keep your systems fast and stable:
1. Multi-Layer Caching
Exact-Match Caching: Utilizes Redis to cache exact prompt parameters.
Semantic Caching: Uses vector databases or Redis vector search to match logically identical prompts, instantly serving cached responses.
2. Retrieval-Augmented Gen
We implement PostgreSQL with pgvector, indexing chunks using HNSW. Hybrid BM25 & vector search retrieves live context safely.
3. Token-Aware Rate Limiting
Traditional request-based limits fail for AI. We deploy Redis token bucket algorithms tracing both TPM and RPM to queue or route requests dynamically.
4. Streaming Response SSE
Generative tokens take seconds to finalize. Streaming tokens via Server-Sent Events (SSE) to display responses in real time.
Enterprise Data Security & Privacy
Sending sensitive company or customer data to public AI services poses security risks. Our AI consultancy focuses heavily on establishing robust data guards, starting with the Gateway Pattern for PII Protection.
Deterministic PII Scrubbing
Middleware scans prompt text using regex patterns (for structured data like phone numbers, API keys, and bank details) and Named Entity Recognition (NER) models (for soft PII like names and organizations) before payloads leave your infrastructure.
Reversible Masking (Rehydration)
Sensitive details are replaced with cryptographic placeholders (e.g., [MASKED_EMAIL_1]) before the prompt is sent to the LLM. Once the model returns the completion, the middleware swaps the placeholders back.
Zero-Data Retention (ZDR)
We guide you through configuring API partnerships with enterprise terms that guarantee customer inputs are never stored, logged, or used to train public foundation models.
Self-Hosted & Offline LLMs
For highly regulated industries, we consult on configuring and hosting secure, offline models (e.g., Llama 3, Mistral, Gemma) inside your private cloud (such as AWS VPC or local servers), keeping data fully within your control.
Our AI Consulting &
Delivery Process
We work with your development and business teams to take your AI integration from concept to production-ready deployment:
Feasibility & Model Selection
We analyze your business goals, map data inputs, evaluate costs versus performance metrics, and select the optimal model size and provider.
Prompt Engineering & RAG
We design system instructions and implement Retrieval-Augmented Generation (RAG) to connect models securely to your private database documentation.
Resiliency & Monitoring
We build caching systems, set up token budgeting, configure failovers, and implement logging to track model latency, toxicity, and accuracy.
Architectural Insights (FAQ)
Deep answers regarding enterprise AI deployments.
Delivery discipline for AI integration systems
We design model orchestrations, vector schemas, custom agent loops, semantic caching layers, and security guardrails before going live.
Statum has operated since 2017 and supports delivery across fintech, logistics, education, retail, and internal operations teams. We work remotely by default, run structured discovery, document scope, and keep stakeholders involved through milestones, sprint reviews, and launch checklists.
2017 (9+ years of shipping enterprise systems in East Africa)
High-volume Fintech, heavy logistics, automated education platforms, and multi-currency retail networks
Agile precision sprints, remote execution, with face-to-face Nairobi steering workshops by appointment
OWASP Top 10 defenses, peer-reviewed access controls, AES-256 encryption, and KDPA-compliant data residency. We enforce SonarQube quality gates, automated threat modeling, and isolated sandboxes that generic agencies ignore.
Plan your next step
Use the links below to review the full services catalog, compare engagement models, see delivery examples, and start a scoped conversation with the team.
Discovery and scope alignment, architecture or implementation plan, sprint delivery, launch readiness, and handover or retained support depending on your team structure.
Build a
smarter enterprise pipeline.
Plan your schemas, guardrails, model choices, and data flows before your cognitive integration project begins.